在 MoE 主旋律之外
近两年的主流大模型发展趋势以 MoE(Mixture of Experts)技术为核心,推动了参数规模和上下文长度的不断攀升。例如 DeepSeek-V4-Pro,其公开参数达到 1.6 万亿(T)总参数量、49B 激活参数并具备 100 万上下文能力,通过极大扩展专家路由的容量,刷新了行业对于大模型极限规模和长上下文场景的认知。类似方案配合高效的 KV Cache 技术,在大规模推理任务与多模态长链路任务中积累了显著优势。业界对 MoE 架构的关注,也带动了上下游对硬件与分布式训练/推理引擎的持续演进。
APEX-2 则选择了一条与主流 MoE 不同的技术路线:以 25B Dense 主干模型为核心,在神经架构与系统工程层面积极优化,探索高效能垂直领域基础模型的实现路径。相比 1.6T MoE 的参数级量级,Dense 主干仅为其约 1/64,但通过底层 Transformer 结构创新、分层 KV Cache 策略、语义码专家残差注入等机制,实现了小体量 Dense 架构对超大 MoE 系统的任务对抗能力。
需要特别指出,APEX-2 并非单纯追求公开榜单测试下的极限分数,而是着眼于金融、医疗、法务、工业等垂直行业的真实生产环境。在这些场景中,模型不仅需要高效处理长上下文和复杂链路,还要兼顾缓存复用率、推理延迟、模型易用性、部署可控性以及专家知识可审计。Dense 架构能够提供连续、稳定的推理通路,并结合可插拔专家注入机制,使得领域知识能够安全、动态地服务于具体业务流程,兼容高安全与高敏感需求的行业场景。
此外,APEX-2 通过结构层面的开放接口,可便捷集成多类型软硬件优化策略,支持弹性扩展。较低的参数规模和高度工程化的 KV Cache 策略使其在资源受限但对数据安全、推理可追溯和分层治理有苛刻要求的领域,展现出独特的系统优势。这种思路为构建高可靠、可持续演进的垂直领域智能系统提供了新的技术范式。
垂直领域:支撑复杂链路与高密度知识挑战的架构设计
垂直领域任务的复杂性远超单轮问答,常涉及跨文档整合、证据链梳理和多阶段决策。以金融风控为例,系统需在多变监管条款与大量实时因子之间动态进行交叉验证,从而快速发现潜在风险;在医疗领域,AI 助手则需要整合病历、诊疗指南与用药禁忌等多源异构信息,及时识别用药冲突、推荐最优路径,实现自动化知识协同;而法务审查场景下,模型还需追溯法律条款冲突、定位案件细节证据并支持全流程可追溯。
这些典型场景对大模型提出了长上下文处理、高一致性、结果可审计与稳定低延迟等多维度严苛需求。Dense 架构的连续推理路径,天然有利于回归分析、灰度测试、效果溯源与可追溯治理。以往 Dense 架构在上下文长度与复杂链路处理上存在一定短板,APEX-2 在此基础上实现了底层工程化创新,重点优化 Transformer 内部结构,通过结构、缓存机制和推理路径的深度融合,有效突破 Dense 在长上下文和多阶段决策下的瓶颈,显著提升系统在垂直场景下的适应力与运行效率。此外,APEX-2 强调从系统底层入手优化,而非单纯依赖外部流程堆叠,从根本上为高密度知识与复杂业务流程提供了可落地与可持续演进的工程基础。
在金融、医疗、法务等垂直领域落地,模型不仅要看通用指标,更要求能够经受实际业务流程的考验与可审计溯源的挑战。APEX-2 架构通过创新性解决方案,实现了实用性与系统安全性的平衡,为行业客户带来真正可用、可管理、可扩展的新一代智能支撑。
APEX-2:Dense-first 底板与模块化堆叠方式
APEX-2 的骨架是 25B Dense 主干,负责通用推理与跨轮状态稳定。其上接入统一的 Transformer 优化栈、分层 KV 管理与语义码总线,使领域能力可以在同一服务进程中持续迭代,而不是拆成多模型串联后做外层补丁。
下图展示了 APEX-2 的研究路线。图中最核心的部分不是输入输出层,而是中间的 Transformer Optimization Stack 与 Context & Memory Optimization——它们共同决定了长上下文推理的吞吐、延迟和可复用能力。
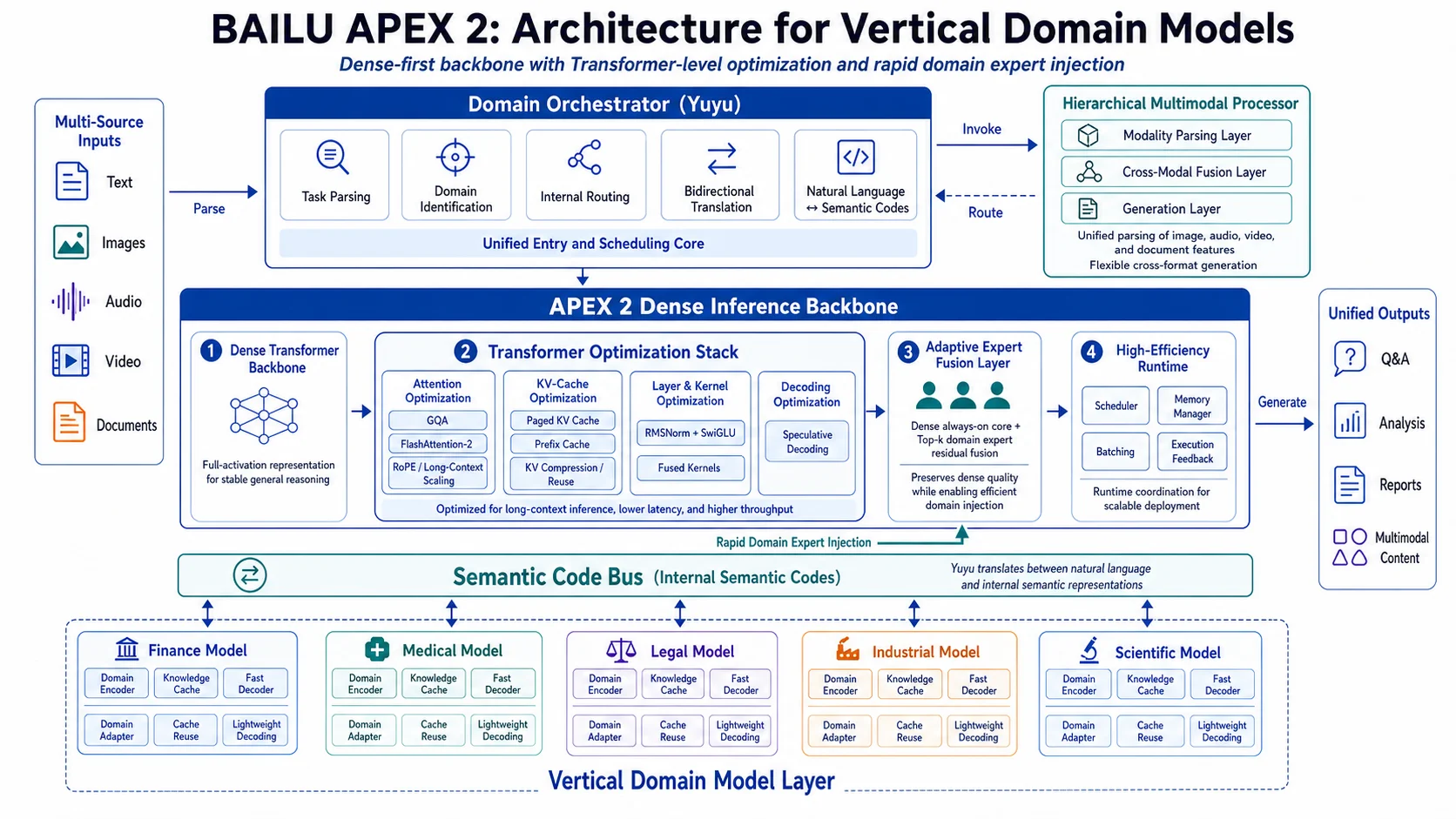
数据流自 Dense 主干 出发,经 注意力优化 与 长上下文策略 进入 分层 KV 管理,再由 解码引擎输出。
领域知识通过 结构化接口动态注入,而不是将整段文档堆进 prompt,通过专家模块有机融合,提升业务适应性与效率。
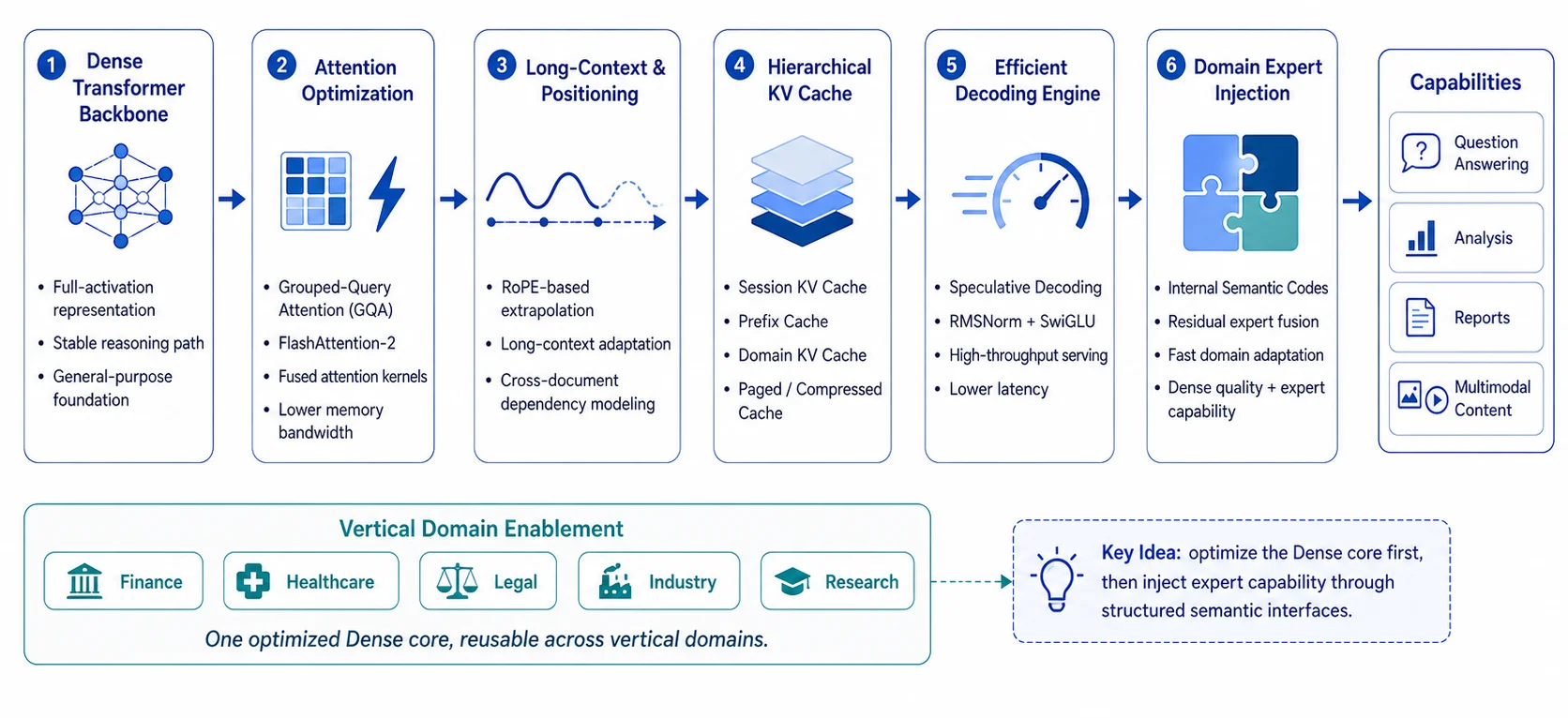
Transformer 底层优化栈
APEX-2 的核心创新聚焦于 Dense Transformer 内部机制的系统性重构,包括注意力路径、KV 存储机制、解码流程以及专家残差注入方式。注意力机制采用 GQA、FlashAttention-2、RoPE 长上下文扩展及混合/稀疏注意力(hybrid/sparse attention),确保在超长上下文场景下实现高带宽与稳定精度。
在上下文与内存管理方面,APEX-2 通过 Paged KV Cache、Prefix Cache、Domain KV Cache 及 KV 压缩与复用,将历史信息由一次性输入转化为高度可控的状态存储。模型层与内核层采用 RMSNorm、SwiGLU、融合算子(Fused Kernels)和算子融合(Operator Fusion),显著降低算子切换与内存访问的系统开销。运行时进一步结合 speculative decoding、动态批处理(dynamic batching)、智能调度(scheduler)与高效内存管理(memory manager),全面提升吞吐量并降低尾部延迟。
领域专家模块在该优化栈中深度原生集成,以语义码与残差路径形式注入模型主干,实现专家能力与主干推理的同路径执行。这种架构便于实现推理一致性验证、缓存高效协同及线上持续回归,为垂直领域的高可靠性与灵活拓展提供了坚实基础。
KV Cache:从显存优化到领域记忆引擎
在 APEX-2 中,KV Cache 不再只是节省显存的工具,更是核心的领域记忆层。它决定了哪些历史状态应长期保留、哪些上下文能够高效复用,以及在高并发压力下,哪些记忆需要智能压缩或分页迁移。面对百万级上下文和多租户应用,系统效率的决定性因素,已经从理论 FLOPs 转向了 KV 管理与调度的精细度。
Session Cache 用于保存当前任务的即时状态;Prefix Cache 让系统提示、任务模板和领域规范高效、多轮次复用;Domain KV Cache 让高频金融、医疗、法务、工业、科研知识在内部如同专属专家一般驻留,并支持细粒度注入;而 Paged/Compressed KV Cache 则支撑着超长上下文和多租户并发下的显存资源弹性分配。APEX-2 不再依赖频繁重读海量领域文档,而是将这些高价值的上下文转化为随时可调用、可追溯、可审计的内部知识状态,显著提升知识的利用效率与系统可维护性。
专业知识注入体系:从语义码到主干结构的精细融合
语义码是一种面向推理过程的高度结构化表示,涵盖实体、关系、约束、证据、索引、图结构与解码约束,其本质在于为模型内部提供可直接解析与调度的信息流。相较于冗长文档摘要和松散知识片段,语义码以精炼且可验证的标记体系,大幅压缩冗余信息,极大提升了知识注入的效率和可控性。APEX-2 架构引入了专用的语义码总线,将专家系统输出以残差信号、有向图结构的形式嵌入 Dense 主干路径,能够实现多源知识融合、自动一致性校验,并显著提升跨领域推理的稳定性和通用性。
在该流程下,Yuyu 作为双向桥梁,精准衔接自然语言、领域语义码与模型内在状态:不仅可以深层解析复杂任务语境和证据信息,还能将丰富推理结果转化为高度可用、可追踪、支持缓存与再利用的结构化数据。APEX-2 专家模块采用分层结构化语义码动态注入,区别于传统 RAG 的文本拼接和 MoE 的 token 级专家路由——不仅能支持更细粒度的实体、链路与依赖注入,还能通过残差融合机制实现专家能力的任务级调用和跨领域复合。系统在底层引入了多路语义码验证、冲突检测、自动降级与融合策略,优化了推理路径的可解释性和可审计性,最大程度减少了信息丢失和推理漂移。
APEX-2 支持语义码缓存抽象层,允许高频领域知识在内存级做持久化、细粒度生命周期管理,实现“热知识”优先复用和低延时召回。动态调度与批处理能力,使多租户及超长上下文下的专家知识注入始终保持高吞吐、低尾延迟,无需频繁重复解析原始语料。对于企业实际应用,系统支持多专家来源动态融合、冲突消解,确保知识注入既安全合规又灵活高效。基于结构化残差,APEX-2 还可自动生成针对核心推理路径的持续回归测试样例和审计链,进一步提升可维护性与生产可用性。
聚焦生产效能,兼顾参数榜表现
与超大规模 MoE 架构的主要区别并不止于参数体量,更在于系统设计对生产实际需求和工程链路的深入把控。APEX-2 在架构层充分考虑了生产环境中的一线需求,重点关注激活路径的连续性、KV 命中率的稳定、专家能力注入的结构化可追踪,以及在私有化与多实例环境下的可维护性与合规性。这些系统层面的优化,帮助规避了“参数冗余、算力浪费”等常见问题,实现以精简主干支持大规模、多样化生产场景的高效落地。
在线上实际应用中,APEX-2 架构能够保持推理激活路径的简明清晰,减少关键路径数量,确保端到端延迟的可控性。借助动态分层 KV Cache 管理体系,整体缓存命中率得到提升,有效减少重复推理和资源消耗;同时,专家能力模块依托语义码与残差融合精准注入主干,不仅可追踪各项能力在推理闭环中的具体影响,为审计与调度优化提供便利。整套架构也具备云到边的灵活迁移能力,权重可直接复用,便于实现企业级私有化部署及合规要求。
APEX-2 着重围绕未来产业实际需求持续优化,以系统工程创新为基础,推动可控性、弹性和可持续优化能力的提升。底层 Dense Transformer 在并发、缓存、调度及专家注入等基础设施环节建立了坚实支撑。与传统 MoE 架构单纯依赖大参数提升性能不同,APEX-2 在资源受限和大规模扩展等场景中,也实现了更优的单位算力转化效率和系统稳定性。
我们希望构建一个既能参与超大规模 MoE 的参数榜单竞争,更突显其推动产业落地的生产能力的边缘端模型。通过优化时延分布、并发压力下尾部延迟、缓存命中率、部署与运维效率等核心系统指标,持续为行业应用保驾护航。在“实效为先、系统为本”的技术路线下,APEX-2 架构让通用模型更接近可控、可维护、可审计的产业级标准,是面向当下实际需求并兼具工程实战性的模型底座之一。
适合垂直领域生产部署
在垂直领域生产部署中,单纯依赖参数规模或纸面性能已无法满足实际需求,系统性能与稳定性才是评判模型价值的核心。企业用户在选择底层模型时,尤为关注时延分布、缓存命中率、尾延迟、审计链路的完善,以及私有化部署的易用性与整体成本。这些关键指标直接关系到系统的可维护性、监管合规、运营效率,进一步影响企业业务连续性与数据安全。
在上述维度上,Dense 主干架构展现了显著优势:高度连续的推理路径大幅降低推理中断和异常跳转,实现更稳定、可预测的输出;边界清晰的测试体系支撑高效的回归验证和灰度发布,优化企业在能力更新和上线过程中的风险与成本。这样的平台基础,让模型能够在持续演进中,安全、低风险地释放新能力,适应不断变化的生产环境。
尤为重要的是,APEX-2通过将专家能力以语义码残差的方式原生注入主干网络,实现了领域知识的可插拔、可缓存、可追踪,并搭建出面向未来的可扩展能力层。领域知识不再分散于 prompt 或临时文档,而是以结构化、高复用的知识单元沉淀在内部,在统一的Transformer 优化栈高效融合与调度,使通用推理与领域适配兼得轻量性和灵活性,从而按需拓展能力,无需频繁更换与全量释出大模型权重。
APEX-2的长期价值体现在:以小巧高效的主干承担通用推理任务,显著降低推理资源开销与部署成本;将领域知识沉淀在专家与缓存层,持续演进并保障可审计性;通过统一优化栈实现端到端系统提效,为大规模多租户、超长上下文和高要求行业生产环境夯实基础。基于这些原生能力,APEX-2 已成为真正面向产业落地、具备持续演化潜力的 Transformer 架构核心。