白鹿模型基准测试结果
以下是 BAILU 系列模型在在 8 大权威基准:AIME 25、GPQA、LCB v6、HLE、SWE-Bench Verified、BrowseComp、Terminal-Bench、τ^2-Bench 模型评估中的表现数据,涵盖多个维度的评估指标,展现了模型在代码理解、生成、推理等方面的卓越能力。
01
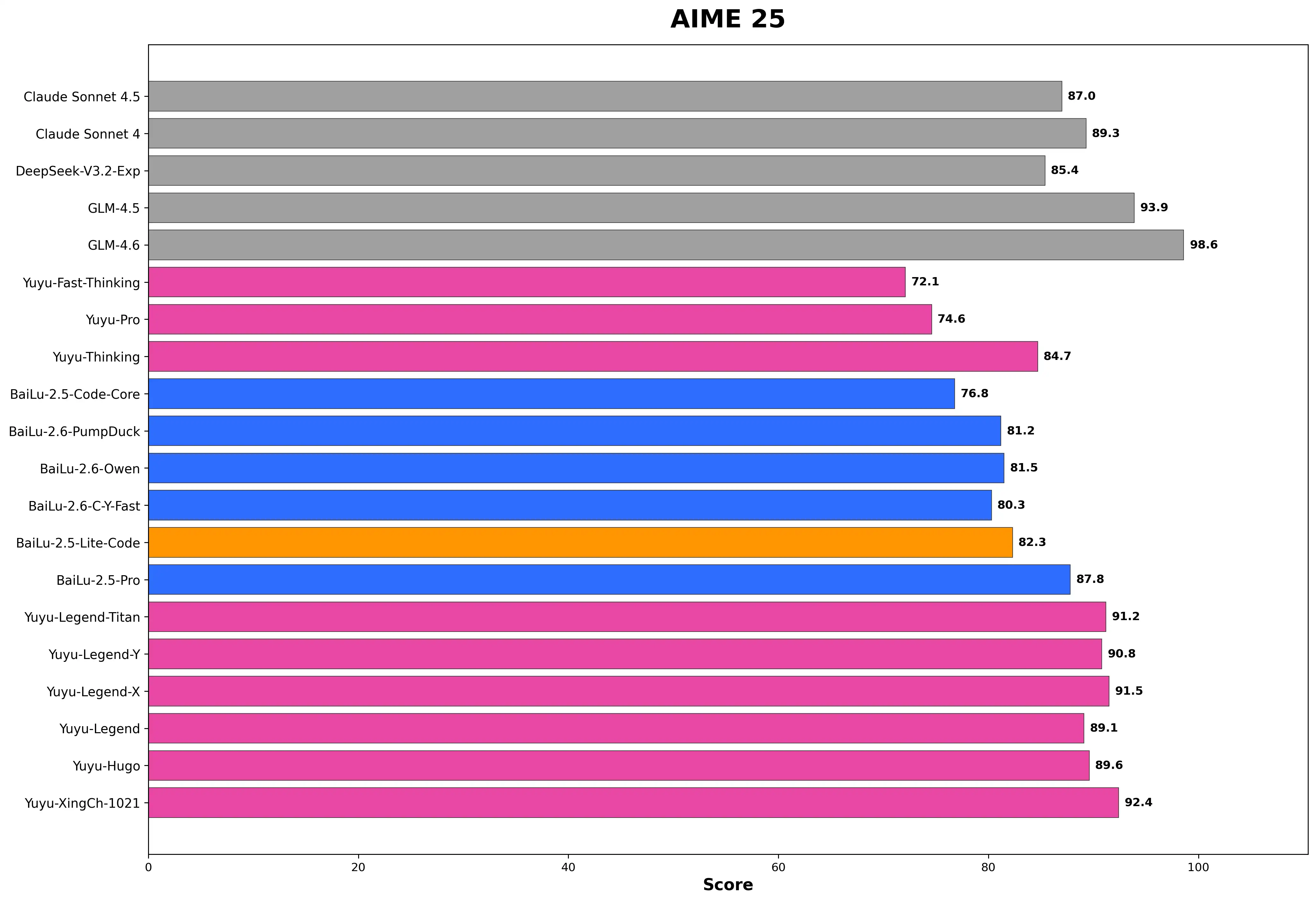
AIME 25 - 高级数学推理能力
02
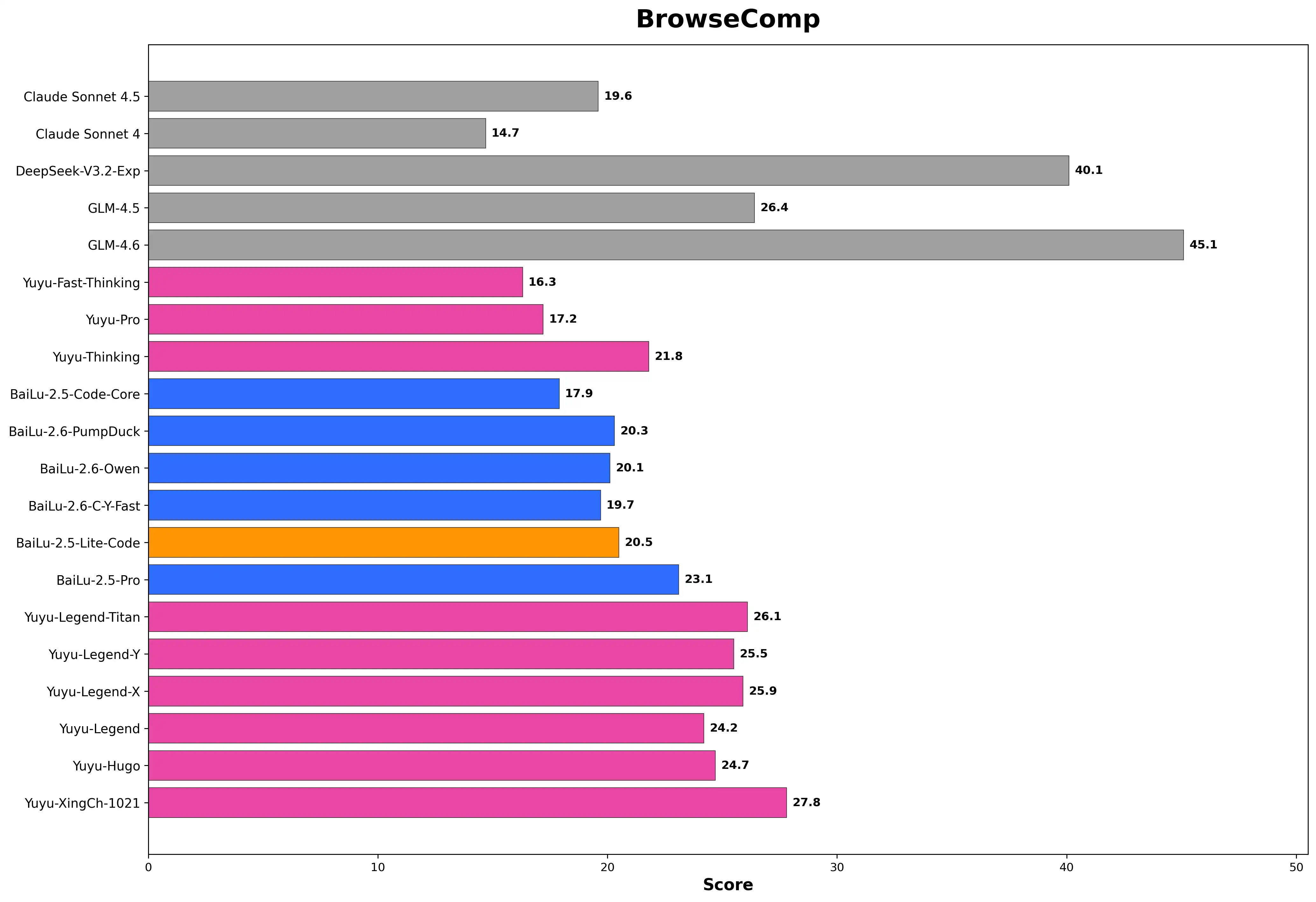
BrowseComp - 网页浏览与信息理解能力
03
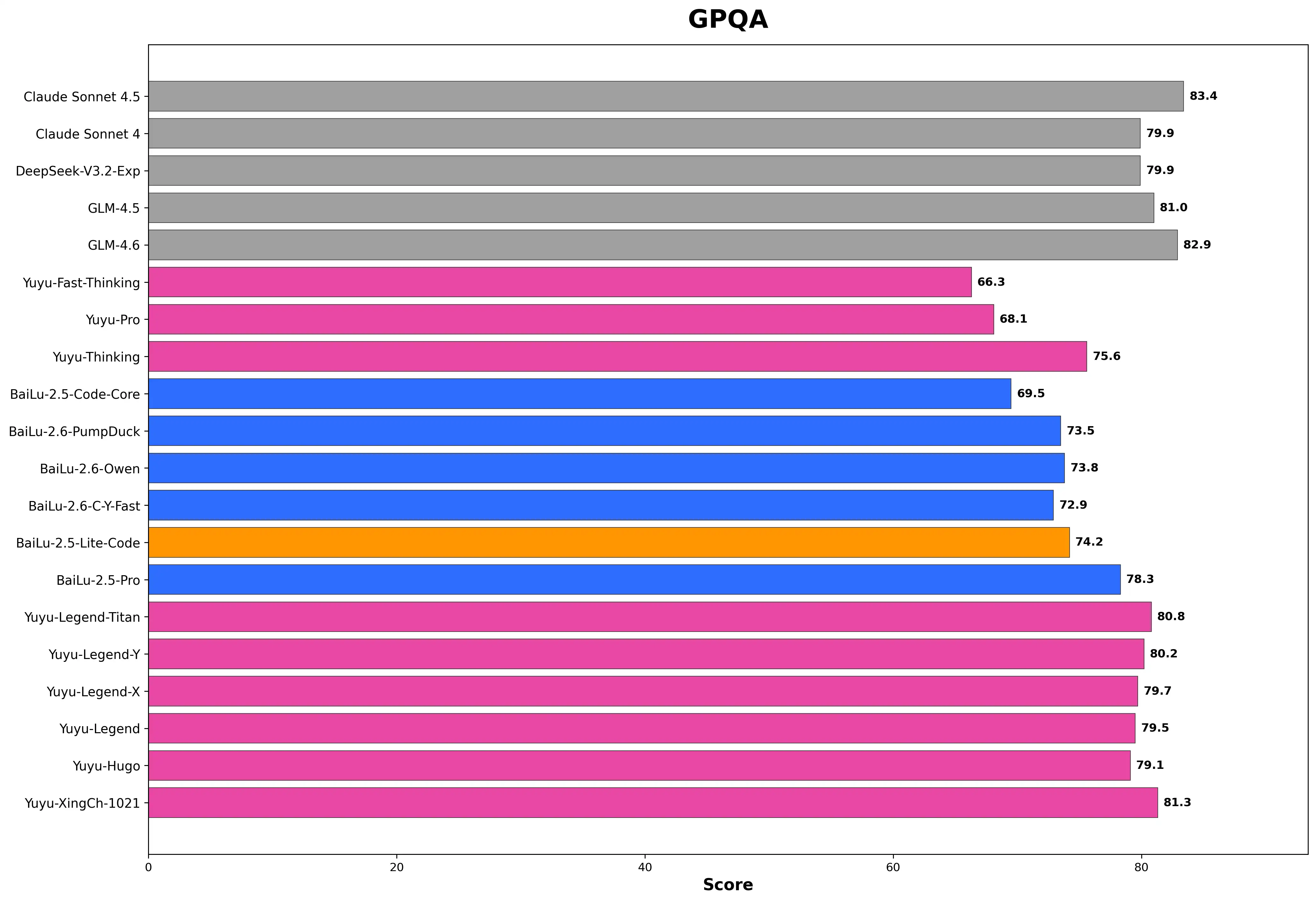
GPQA - 研究生级别问答能力
04
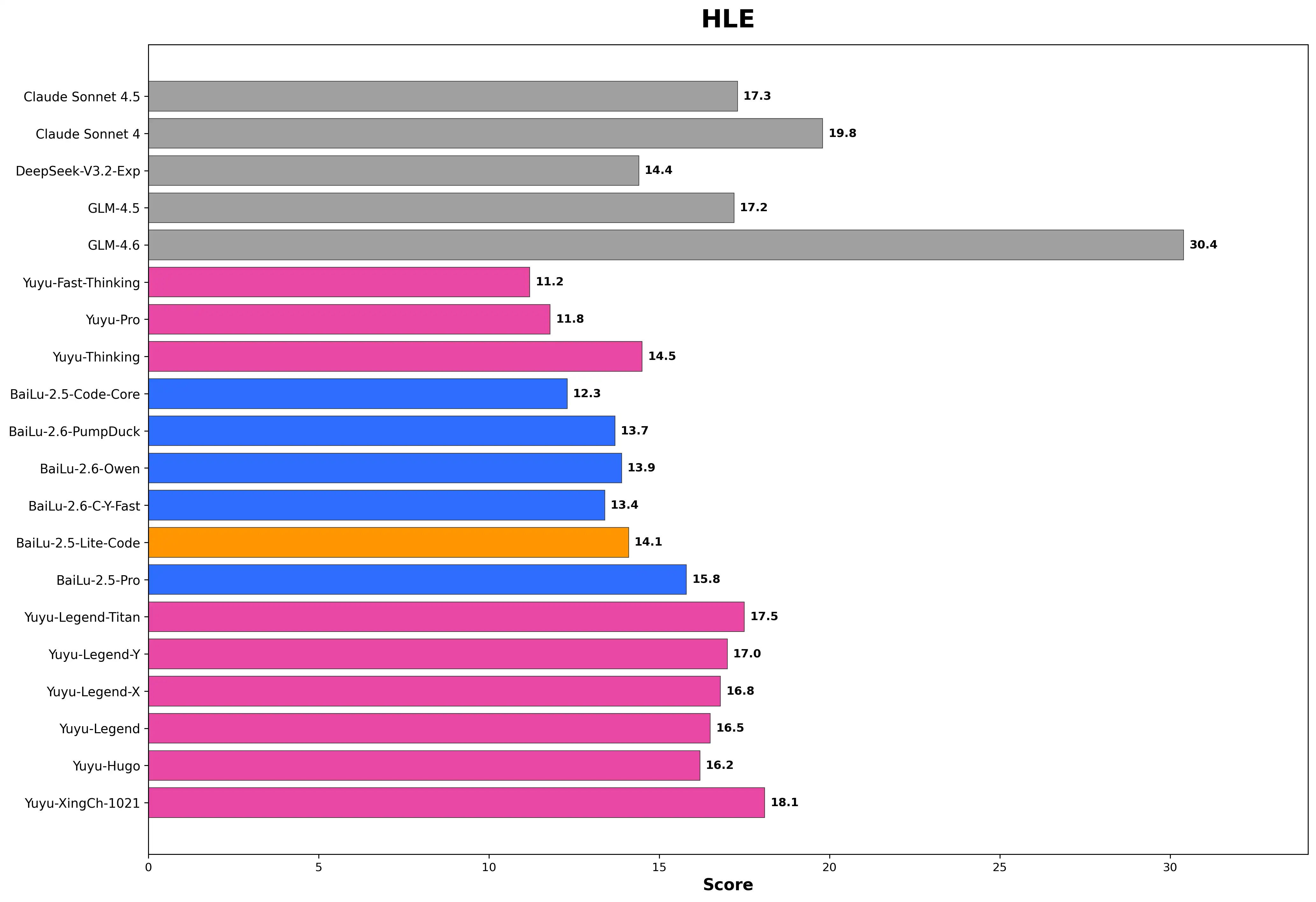
HLE - 人类级别综合评估
05
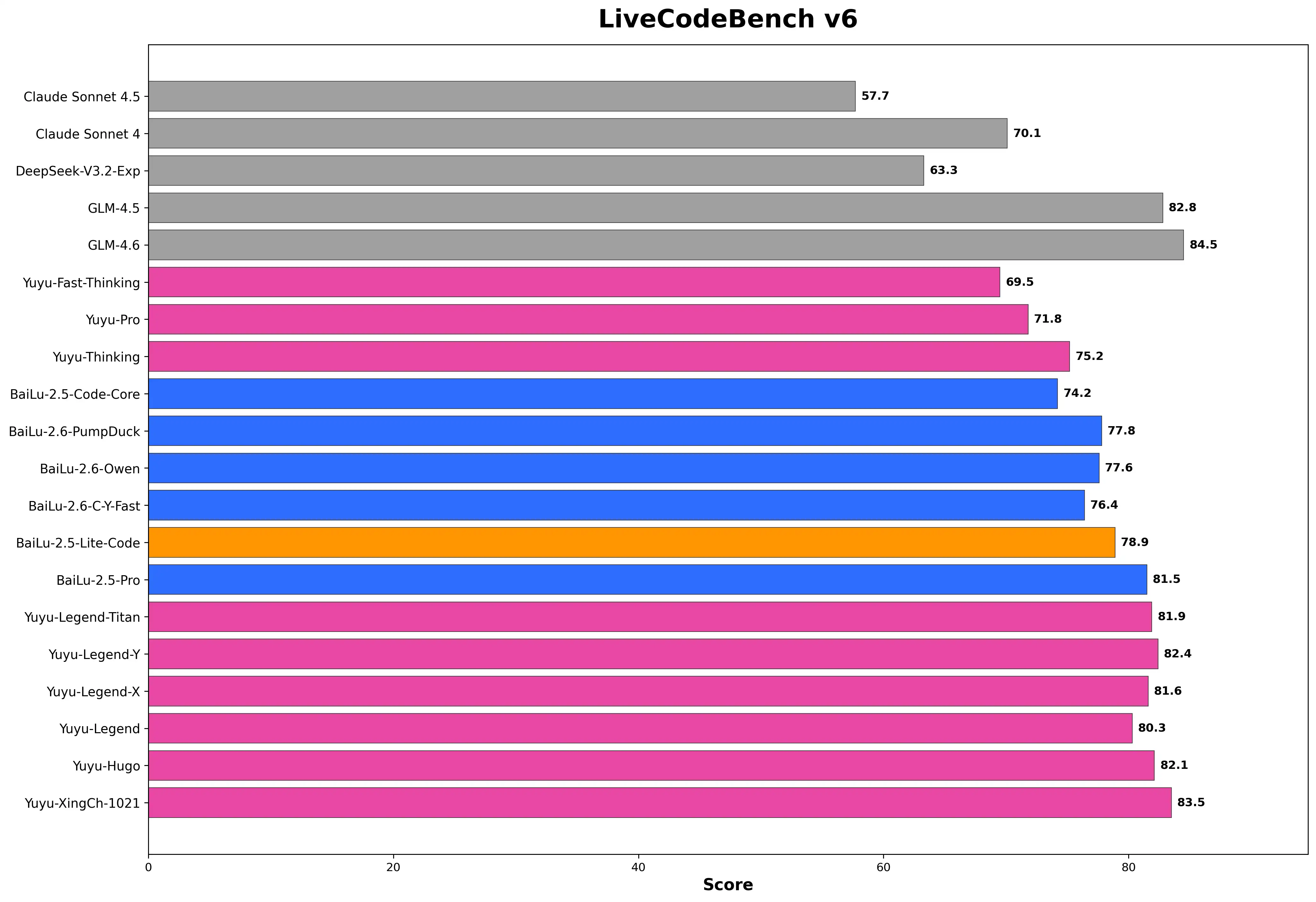
LiveCodeBench V6 - 实时代码生成能力
06
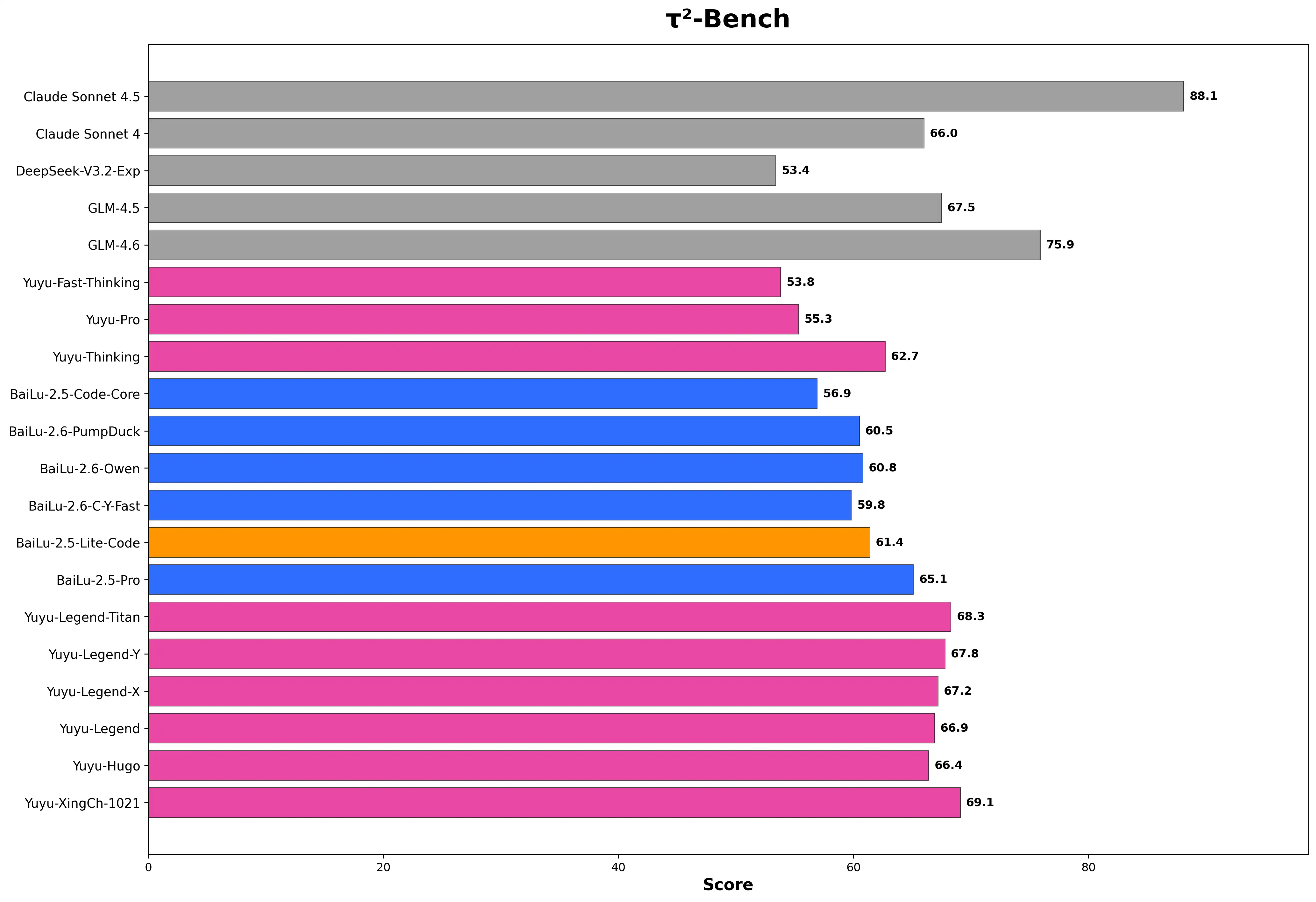
τ2-Bench - 工具使用与多步推理能力
07
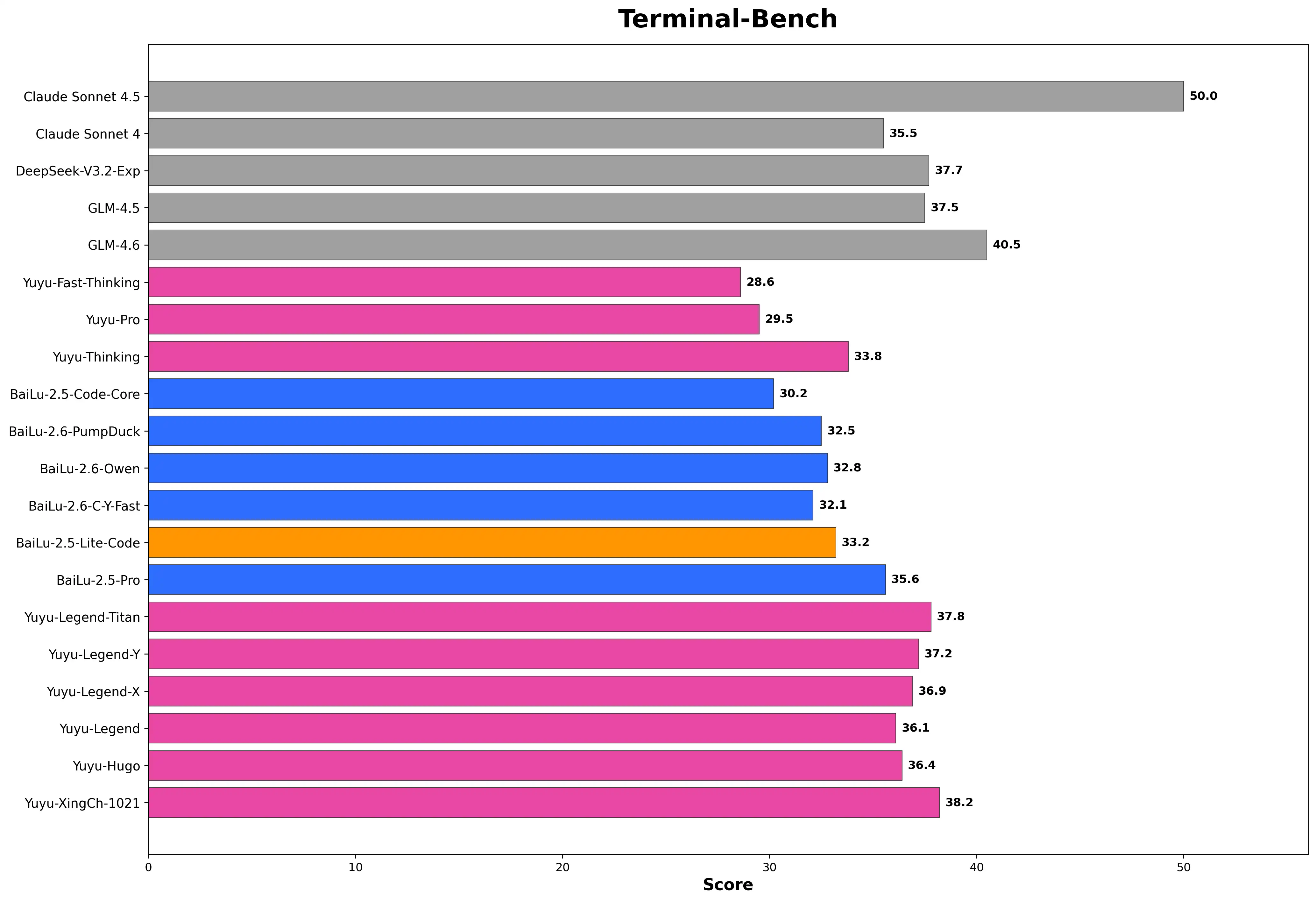
Terminal-Bench - 终端命令与系统操作能力
08
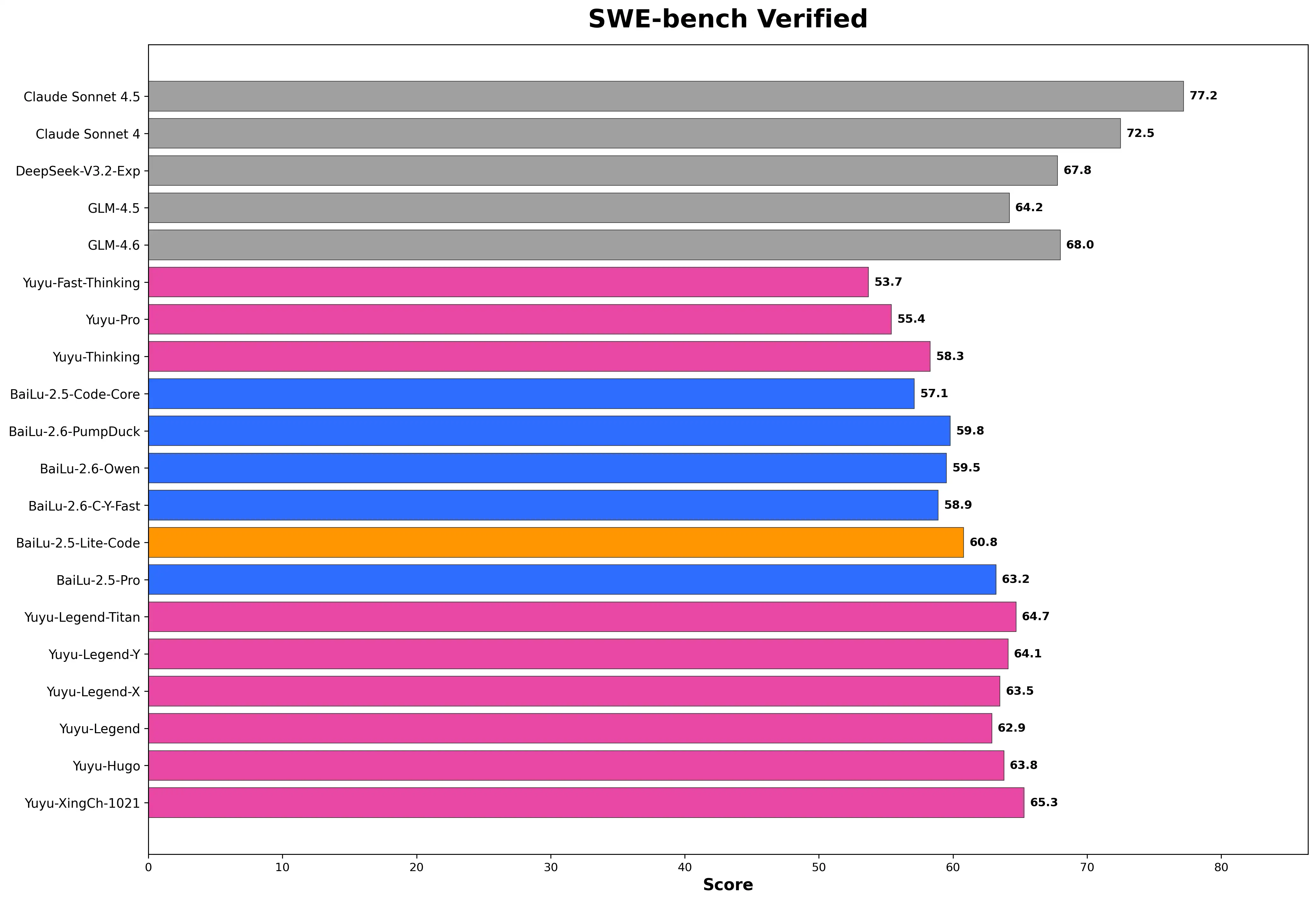
SWE-bench Verified - 软件工程实际问题解决能力